
엔지니어로 여러 업무들을 수행하다보면 JSON 문자열과 자주 만나게 됩니다.
(서버 목록을 뽑는다거나, Request Parameter를 분석한다거나…)
특히나 cli 커맨드를 통해 주고 받는 데이터를 원하는 포맷으로 가공하거나 보고 싶을 때가 많은데, jq라는 툴을 사용하면 손쉽게 cli 커맨드 영역 안에서 JSON을 핸들링(필터링)할 수 있습니다. (스크립트를 짜거나, 텍스트 에디터를 통해 일일이 수정하지 않아도 됩니다)
이미 많은 분들이 사용하고 계시지만, 그동안 유용하게 사용하고 있던 jq 기능의 기초와 자주 사용하는 사용 사례들을 공유하고자 합니다. (사실 제가 참고하기 위함)
jq란?
jq는 전달받은 JSON 데이터를 손쉽게 접근하고 가공할 수 있는 light weight 프로세서입니다. 간단한 문법을 통해 원하는 데이터를 검색할 수 있고, 필터링할 수 있으며 이를 재가공해서 다른 포맷으로 변환할 수도 있습니다. (제공되는 기능이 정말 많습니다)
사실은 jq가 있기 이전에도 이와 비슷한 기능을 제공하는 툴들은 많이 존재해왔습니다. jq의 영감이 되기도 한 sed 도 그렇고, sed, awk, grep 모두 CLI에서 텍스트를 편하게 핸들링하기 위한 수단으로써 개발되어 왔습니다.
jq 또한 마찬가지로 ‘텍스트’ 그 중에서도 JSON 데이터를 쉽게 다루자는 의의에서 개발되었으며, 여러 OS를 지원하기 때문에 맞는 버전만 설치하면 어디서든 동일한 문법으로 사용할 수 있습니다 (약간의 차이는 있습니다)
“jq is like sed for JSON data”
- jq project document
아래는 jq를 통해 JSON 데이터를 가공한 간단한 예시입니다. 역시 설명보단 실제로 사용해보는 것이 빠르기 때문에, 바로 설치 방법부터 간단한 문법까지 보겠습니다.
$ cat test-data.JSON | jq '.["name"].[]'
설치 방법
jq는 많은 패키지 매니저들이 기본적으로 제공하는 라이브러리 중 하나 입니다. 각 OS마다 지원되는 패키지 매니저에서 아래와 같이 손쉽게 설치가 가능하며, 아래는 MacOS에서는 homebrew를 통해 설치하는 예시입니다.
$ brew install jq
윈도우의 경우도 winget 또는 chocolatey를 통해 아래와 같이 설치가 가능합니다.
# $ winget install jqlang.jq
$ chocolatey install jq
이 외에도 각 OS마다 설치법이 공식 문서에 안내되어 있으니 참고하셔서 다운 받으시면 됩니다.
문법
jq 문법은 기본 구조만 이해하시면 나머지 필요한 필터들은 공식문서에서 키워드를 통해 찾아 사용하실 수 있습니다. 필터들이 문서화가 정말 잘 되어 있기 때문에 문서상의 사용 예시를 참고하시면 되며, 그럼에도 이해가 안될 시 해당 문법을 테스트해볼 수 있는 사이트도 제공되고 있습니다.
(문법도 많아서 공식 문서에서 문법 찾는게 일이에요.)
아래 예시는 맛보기 정도로 어떻게 사용될 수 있는지 흐름만 이해해주시면 좋겠습니다.
내 상황에 맞는 필터들은 공식 문서를 참고해보세요 😉
기본 구조
jq의 기본적인 문법은 jq 커맨드에게 데이터 스트림을 넘겨주는 방식입니다. 이 때, jq 커맨드의 인자값으로 쿼리를 넘겨주어 필요한 필터들이나 개체를 선택하는 방식으로 사용하게 됩니다.
# 파이프 문법을 통해 jq 커맨드의 input으로 test.json 파일의 데이터 스트림을 넘겨줌
$ cat test.json | jq
# 이외에도 다양한 쿼리 방식은 있음. 결국 데이터 스트림만 jq 커맨드에 잘 넘겨주면 됨
$ jq '.' test.json
쿼리는 보통 . 으로 시작되며, 이 점은 하나의 개체(identity)를 의미합니다. 이 데이터가 JSON 개체라는 것을 알려주는 것이죠. 물론, . 또한 Array나 Object로 감쌀 수도 있습니다.
처음 .이 사용되면 input으로 넘겨준 JSON의 최상단을 가리키고 있습니다. 이후 한 계단씩 원하는 데이터를 찾을 때까지 JSON을 drill down하며 문법을 작성해나가면 됩니다.
$ cat test.json | jq '.' # 현재 개체를 선택만 한 상태 (input, output 같음)
JSON 데이터를 쿼리하는 방법은 데이터의 타입에 따라 다릅니다.
Object
Object 타입의 경우 Key 이름을 .의 다음 값에 명시해주면 되며, Key를 명시하는 방법은 크게 두 가지 있습니다. 실제 사용법은 아래 예시를 통해 살펴보겠습니다.
- 가장 기본적인 방식인
["key"]형식의 대괄호를 활용한 방식 - 대괄호와 쌍따음표를 생략하고 바로 키 값을 넘겨주는 방식
먼저, 아래는 앞으로의 예시에서 사용될 예제 JSON 파일입니다.
# test.json 파일 내용
{
"name": "dohun lee",
"description": "대략적인 설명",
"role": "devops engineer",
"address": {
"country": "Korea",
"city": "Seoul",
"street address": "일급 비밀"
},
"pet": [
{
"name": "sogum",
"type": "cat",
"age": 5
},
{
"name": "yamato",
"type": "shrimp",
"age": 2
}
]
}
위와 같은 Object 데이터에서 role 이라는 이름을 가진 데이터를 쿼리하고 싶다면 아래와 같이 실행하면 됩니다.
# 아래 두 커맨드는 동일한 커맨드
$ cat test.json | jq '.["role"]'
$ cat test.json | jq '.role'
위 문법에서 .["role"] 는 .role 과 같이 생략되어 사용될 수 있습니다. (다만, 키 값에 공백이 포함되는 경우 문법상 에러가 날 수 있으니 그런 경우는 대괄호를 사용해 키 값을 명확히 명시해줍시다.)
# output
"devops engineer"
그런데 위 Object의 address 데이터와 같이 데이터의 반환값이 문자열이 아닌 또 다른 Object인 경우, 그대로 Object를 반환받아도 되지만 street address 라는 이름의 값만 추출하여 사용할 수도 있습니다.
방법은 위와 마찬가지로 다시 개체를 선택해주고 street address 라는 키 값으로 데이터를 쿼리하면 됩니다.
# 아래 두 커맨드는 같은 커맨드
$ cat test.json | jq '.["address"].["street address"]'
$ cat test.json | jq '.address["street address"]'
# output
"일급 비밀"
참고로
.문법은 최초에만 사용하면 되며,[]대괄호를 선택자 문법으로 사용하는 경우.은 생략될 수 있습니다. (대괄호를 생략하는 경우에는.필수)
Array
Array의 경우 Array 전체를 탐색하며 반복문을 수행하는 방법이 있고, 원하는 index를 선택해 탐색하는 방법이 있습니다.
먼저 index를 이용해 하나의 데이터에 접근할 때는 배열의 index를 기존 선택자 뒤에 대괄호로 명시해주면 됩니다. (Array의 경우 대괄호 생략이 불가합니다.)
$ cat test.json | jq '.pet[0]'
# output
{
"name": "sogum",
"type": "cat",
"age": 5
}
마찬가지로, 반환 값이 Object라면 선택자로 key 정보를 넘겨줘 원하는 값만 필터링할 수 있습니다.
$ cat test.json | jq '.pet[0].name'
# output
"sogum"
만약 배열의 전체를 반복문을 돌며 필터링하거나 접근하고 싶은 경우, index를 명시하지 않고 전체를 호출하거나, 특정 index 구간을 선택해 원하는 데이터들만 호출할 수 있습니다. 방법은 마찬가지로 대괄호를 사용하면 되는데, 아래와 같이 대괄호 안에 아무런 값을 명시하지 않으면 배열 전체가 반복문을 돌며 호출됩니다.
$ cat test.json | jq '.pet[]'
# output
{
"name": "sogum",
"type": "cat",
"age": 5
}
{
"name": "yamato",
"type": "shrimp",
"age": 2
}
배열의 각 개체들에서 name만 추출하고 싶다면 아래와 같이 사용하면 됩니다.
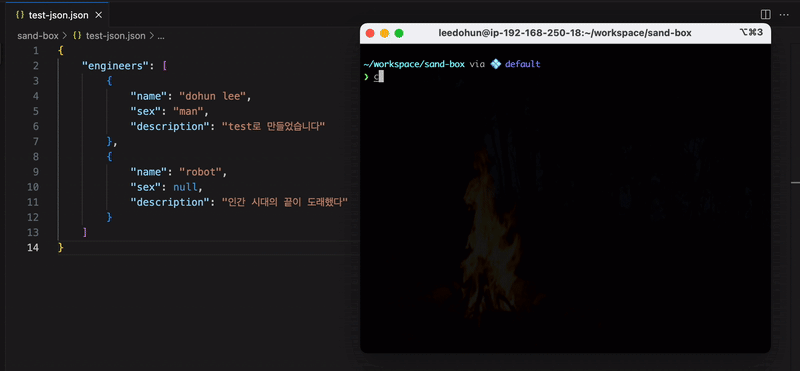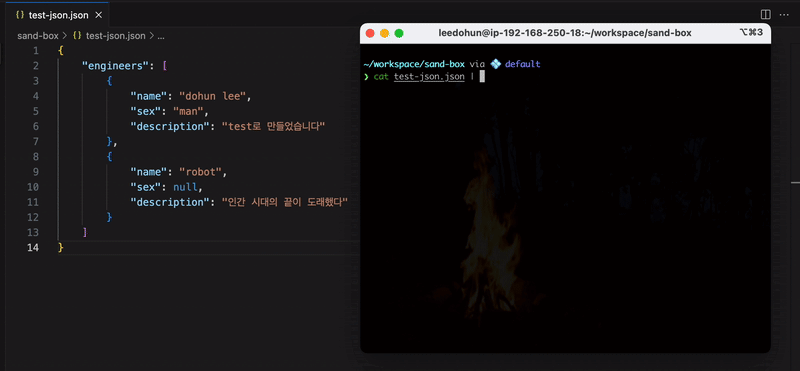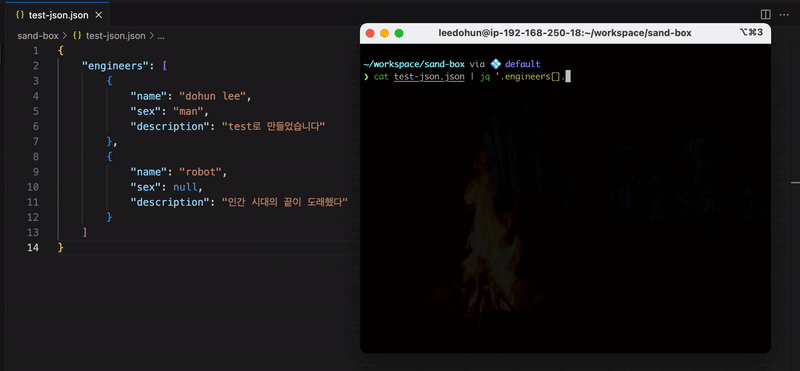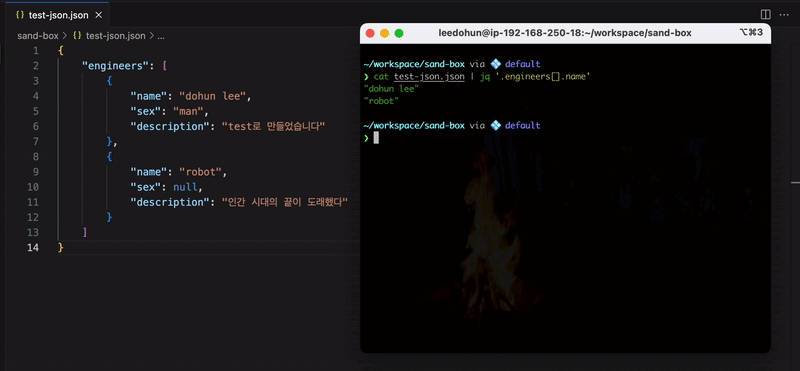
$ cat test.json | jq '.pet[].name'
# output
"sogum"
"yamato"
파이프라이닝
파이프 문법은 Linux에서 사용되는 파이프 | 문법과 동일한 기능을 제공하고 있습니다. 데이터를 필터링할 때 자주 쓰는 방식으로, 앞선 jq 문법에서의 output을 다음 문법의 input으로 쓰거나, 필터 문법을 사용해 앞선 jq 결과물을 필터링할 수 있습니다.
먼저 아래와 같이 파이프 문법을 통해 앞선 jq 쿼리의 결과물을 다음 jq 쿼리의 input으로 사용할 수 있습니다.
$ cat test.json | jq '.pet[] | .type'
# output
"cat"
"shrimp"
또는, select, entry와 같은 jq 함수들을 통해 원하는 값을 필터링할 수도 있습니다.
$ cat test.json | jq '.pet[] | select(.type == "cat")'
# output
{
"name": "sogum",
"type": "cat",
"age": 5
}
계속해서 파이프 문법을 사용해 원하는 값까지 도달할 수 있습니다.
$ cat test.json | jq '.pet[] | select(.type == "cat") | .age'
# output
5
실제 사용 사례

이제는 위 문법들과 추가적인 필터들을 이용한 실제 사용 사례들을 몇 가지 다뤄보겠습니다.
(계속해서 추가 될 예정)
1. AWS CLI 결과물 정리
AWS 리소스 목록이나 상태를 보기 위해 list나 description을 요청해보면 Response가 상당히 방대합니다. 저희는 이 중 필요한 데이터만 추출하고 나머지 불필요한 데이터는 제거하고 싶습니다. 이를 json으로 다시 정리해두면 읽기도 참 편할 것 같네요!
우선 jq 쿼리를 짜기 전에, Response JSON의 데이터 구조를 먼저 보는게 좋겠습니다. JSON 구조를 알아야 쿼리 내에 놓치는 부분 없이 깔끔하게 추출이 가능합니다. 만약, 사전에 데이터 구조 확인이 어렵다면 한 번 필터 없이 데이터를 조회해보고 파일에 저장하여 참고하면서 작성하는 것도 방법이 되겠습니다 🙂
한 번 예시로 Route53 Record들을 리스팅해보겠습니다. 이 중에서 저는 CNAME 타입의 레코드 도메인 이름만 리스팅 해보겠습니다.
설명이 엄청… 기네요, 한 번 실행해서 대략적인 구조를 보는게 더 간편하겠습니다
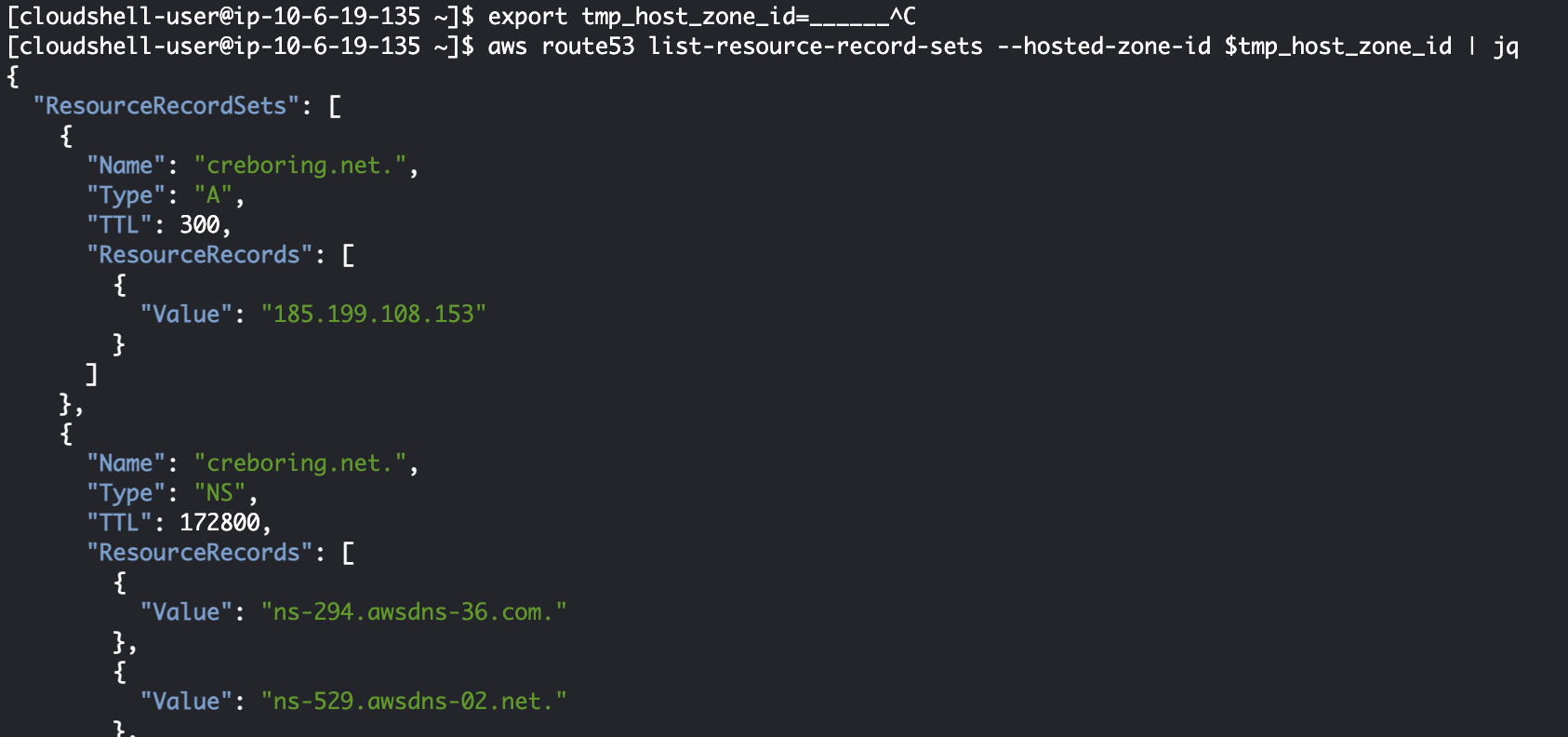
레코드를 담는 Object는 최상단부터 ResourceRecordSets → (Array) → (Reord Object) 형식으로 저장되는 것으로 보이는군요 🤔 이 구조를 참고하여 필터를 만들어보겠습니다. 먼저 레코드 타입이 CNAME인 데이터를 추출해봐야겠네요
$ aws route53 list-resource-record-sets --hosted-zone-id $tmp_host_zone_id \
| jq '.ResourceRecordSets[] | select(.Type == "CNAME")'
# output
{
"Name": "dohun.creboring.net.",
"Type": "CNAME",
"TTL": 300,
"ResourceRecords": [
{
"Value": "creboring.net"
}
]
}
{
"Name": "test-dns.creboring.net.",
"Type": "CNAME",
"TTL": 300,
"ResourceRecords": [
{
"Value": "www.naver.com"
}
]
}
원하는 데이터가 잘 추출되었습니다! 이제 결과값의 Name, ResourceRecords 필드로 새로운 Object를 만들어 보겠습니다. CNAME은 레코드 값을 항상 하나만 가지고 있으니 ResourceRecords 값은 배열의 첫번째 Value만 사용할게요.
$ aws route53 list...(이하 생략) \
| jq '.ResourceRecordSets[] | select(.Type == "CNAME") | {"name": .Name, "value": .ResourceRecords[0].Value}'
# output
{
"name": "dohun.creboring.net.",
"value": "creboring.net"
}
{
"name": "test-dns.creboring.net.",
"value": "www.naver.com"
}
원하는 데이터 포맷으로 가공도 완료되었네요 😎
2. Github Action Step output
배포 파이프라인을 구성하다 보면, 이전 Step의 output을 다음 Step에서 사용할 때가 있습니다. 특히 외부 라이브러리를 호출한 결과물을 다음 Step에서 써야 한다면, Step에서 필요로하는 포맷으로 결과물을 가공하여 전달할 필요가 있습니다.
Github Action을 통해 Cloudflare 캐시를 무효화하는 모듈을 만드려 합니다. 이 캐시 무효화 API에서는 zone_id 라는 고유값을 필요로 하기 때문에 아래와 같은 두 Step으로 만들어보겠습니다.
- zone에서 사용하는 도메인 이름을 입력받아 zone_id를 반환해주는 Step
- 전달받은 zone_id를 통해 캐시 무효화(Purge)를 수행하는 Step

Cloudflare도 문서에 Response 명세가 잘 되어 있네요. result → (Array) → (Zone Object) 값을 참조하면 zone_id를 갈취할 수 있을 것 같습니다. 조금 더 확인해보니 Zone Object들의 name 값이 도메인, id가 zone_id를 가리킨다고 하네요!
steps:
- name: Get CloudFlare Zone ID
id: get-cloudflare-zone-id
shell: bash
run: |
ZONE_ID=$(curl --request GET \
--url https://api.cloudflare.com/client/v4/zones \
--header 'Authorization: Bearer _____' \
--header 'Content-Type: application/json' | jq '.result[] | select(.name == "test-domain.com") | .id')
echo "ZONE_ID=$ZONE_ID" >> $GITHUB_OUTPUT
# output
"77776666555544443333222211110000" # zone_id
name key를 select 필터에서 사용하고 id 개체를 가져오도록 구현하니 원하는 zone_id를 output으로 잘 가져올 수 있었습니다
이제 잘 가공된 output을 다음 Step에서 사용만 하면 되겠네요 🙂
3. JSON을 다른 포맷으로 변환
jq는 output을 JSON이 아닌 csv나 yml 포맷으로 변환할 수 있는 기능도 제공하고 있습니다. yml 포맷은 가독성이 좋아 manifest 파일 포맷으로 많이 사용되고, csv 파일은 저장해두었다가 엑셀에서 열어볼 수 있기 때문에 요구사항에 따라 다른 포맷으로의 변환도 가능합니다.
하루 동안의 특정 EC2 서버의 CPU 사용량을 엑셀에 정리하여 1시간 단위로 80%가 넘어가는 시간대에 색을 칠하고 싶습니다. (80%가 넘지 않는 시간대도 리스팅은 해야 합니다)
먼저, jq를 통해 AWS CLI Response JSON 데이터에서 필요한 값들을 csv로 추출한 다음 엑셀에서 조건부 서식으로 색을 칠해주면 되겠네요.
aws cloudwatch get-metric-statistics \
--namespace AWS/EC2 \
--metric-name CPUUtilization \
--start-time 2024-01-20T00:00:00Z \
--end-time 2024-01-21T00:00:00Z \
--period 3600 \
--statistics Maximum \
--dimensions \
Name=InstanceId,Value=${INSTANCE_ID}
# output
{
"Label": "CPUUtilization",
"Datapoints": [
{
"Timestamp": "2024-01-20T20:00:00+00:00",
"Maximum": 14.16336188222748,
"Unit": "Percent"
},
{
"Timestamp": "2024-01-20T02:00:00+00:00",
"Maximum": 8.212013192524237,
"Unit": "Percent"
},
# ...(이하 생략)
]
}
먼저 필터 없이 쿼리하여 데이터 구조를 확인했으니 필요한 값들을 추출해봅니다. 다음으로 @csv 구문을 파이프로 넘겨주면, 앞선 데이터의 포맷을 csv 포맷으로 변환하여 출력해줍니다.
aws cloudwatch get-metric-statistics \
--namespace AWS/EC2 \
--metric-name CPUUtilization \
--start-time 2024-01-20T00:00:00Z \
--end-time 2024-01-21T00:00:00Z \
--period 3600 \
--statistics Maximum \
--dimensions \
Name=InstanceId,Value=${INSTANCE_ID} \
| jq '.Datapoints[] | [.Timestamp, .Maximum] | @csv'
# output
"\"2024-01-20T20:00:00+00:00\",14.16336188222748"
"\"2024-01-20T02:00:00+00:00\",8.212013192524237"
"\"2024-01-20T07:00:00+00:00\",9.441495998802136"
"\"2024-01-20T05:00:00+00:00\",8.969955650405149"
# ...(이하 생략)
데이터가 csv로 잘 추출되었으니, 남은 일은 엑셀에서 조건부 서식만 걸어주면 되겠습니다 🙂
정리
CLI 커맨드를 쓰다 보면 각 커맨드에 필터 옵션이 내장된 경우들도 많지만 그렇지 않은 경우 jq와 같은 유틸리티 툴이 상당히 유용하게 사용됩니다. 결국 손에 익어야 유용하게 사용 가능하기 때문에, 유용한 사용 사례들이 생길 때마다 추가할 예정이니 좋은 의견이나 사례가 있으시면 공유주세요!
